

Over the years, Picnic has achieved multiple milestones and overcome numerous challenges. Our warehouses continue to expand, our product assortment grows, and we now deliver goods to even more families. Behind this growth lies a complex network of interconnected systems, all working together to support our operations. At the core of this intricate ecosystem are certain fundamental concepts that drive consistency and reliability across all our systems.
One such core concept is identifiers — for example, the unique IDs assigned to warehouses — such as FC6, FCA and others. These identifiers play a pivotal role in linking various processes, from inventory management to logistics and order fulfilment. As Picnic’s systems expanded to accommodate international operations, it quickly became clear that the existing identifier format was no longer sufficient to uniquely represent a warehouse. For instance, the identifier for FC6 in the Netherlands could not reliably distinguish it from warehouses in other markets, leading to potential confusion and operational challenges. This realisation led to the development of a new, more versatile identifier strategy. However, with this advancement came a critical challenge: how to ensure the seamless adoption of these new identifiers across all Java-based systems without disrupting day-to-day operations.
The challenge was further compounded by additional requirements:
- Minimized microservice rework: The transition needed to occur without requiring teams to rewrite or heavily modify their existing services;
- Phased implementation: A gradual rollout was essential to avoid the risks associated with “big-bang” deployments, which are inherently error-prone and challenging to synchronize across distributed systems.
A seemingly straightforward solution is to introduce a new API alongside the old one. This new API then uses the updated identifier format, allowing clients to migrate incrementally and independently. While this approach appears practical at first glance, it comes with a significant drawback: teams would need to maintain two sets of API entities in parallel as well as two sets of endpoints, resulting in long-term operational overhead and an increased likelihood of errors due to duplicated logic.
Given these challenges, a different solution was needed — one that would enable a seamless transition without burdening development teams or jeopardizing system stability. We asked ourselves: can we develop specialized tooling or mechanisms to facilitate the migration from the old identifier format to the new one within our technical stack of Java and Spring? If so, that would simplify the transition and also future-proof our systems for continued growth and scalability.
Finding the force in Spring and Jackson
In light of the various constraints and requirements, we designed a shared Java library to address the challenges effectively.
The first key step was to introduce an intermediate transition entity. This entity serves as a bridge by maintaining both the old and new IDs simultaneously, enabling seamless usage of either ID as needed during the transition phase.
public record TransitionId(String oldId, String newId){}Next, we implemented a specialized Jackson deserializer. This key component was designed to convert an incoming string — whether in the old or new format — into the intermediate transition entity. In cases where an unknown string format is encountered, the deserializer handles the situation by throwing an exception and failing fast.
The deserializer facilitates smooth API interactions, allowing client applications to pass either old or new IDs without any modifications. This transparent handling ensures backward compatibility while paving the way for a seamless migration: in other words, the API entity change does not alter the JSON representation in any way; the migrated field continues to be represented as a simple String within the JSON structure (here, we refer specifically to the JSON representation as it is the most widely used format; however, the concept applies equally to other formats, such as XML, TSV and others). Although it sounds trivial, the underlying process is far more intricate than it might initially appear.
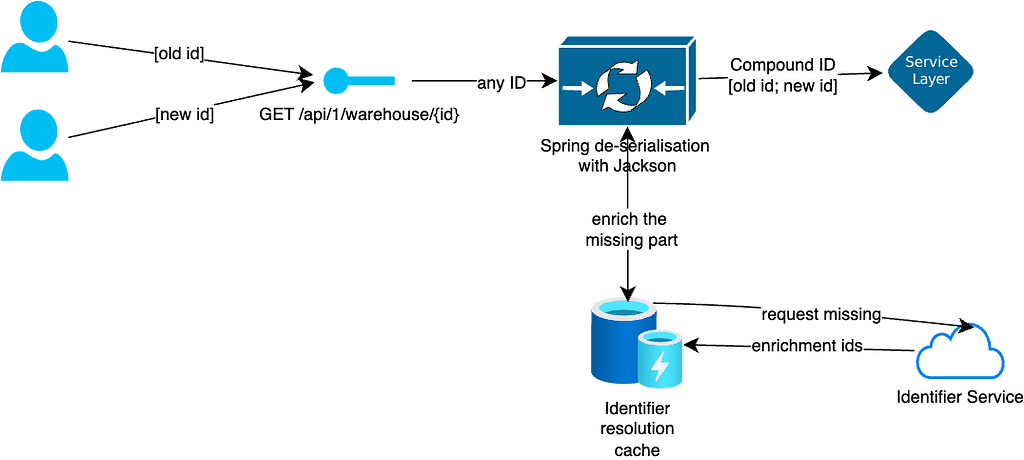
One of the most critical components of this solution is the need for a data cache or repository capable of resolving both old and new IDs into their corresponding transition IDs. This cache must be populated early in the Spring application lifecycle, as other startup processes or dependent caches may rely on the resolution of transition IDs. Once this cache is populated and operational, the deserializer efficiently handles all subsequent ID transformations.
A significant advantage of the Jackson approach lies in its versatility. By registering the deserializer class within the Jackson ObjectMapper as a regular deserializer, key deserializer and converter, we ensure its applicability across the Spring context, including @PathVariable and Map<?,?> keys. Essentially, this approach ensures coverage of all potential use cases for the TransitionId while offering the broadest possible support.
Moreover, this approach seamlessly integrates with entities used in Spring controllers and RabbitMQ events. Since these rely on ObjectMapper for deserialization, the solution does not require additional configuration adjustments to extend its functionality across various system components. All configurations are encapsulated within a generic library, abstracting the complexity away from the end-user. This library can be seamlessly integrated into any project undergoing migration, ensuring a streamlined and hassle-free implementation process.
Let’s consider this example application with a quite trivial endpoint:
@RestController
@RequestMapping("/api/1/deserialization/test")
class DeserializationDummyController {
@GetMapping("/{id}")
Object getWithPathVariable(@PathVariable String id) {
return dummyService.process(id);
}
}
The migrated endpoint would look like the following:
@RestController
@RequestMapping("/api/1/deserialization/test")
class DeserializationDummyController {
@GetMapping("/{id}")
Object getWithPathVariable(@PathVariable TransitionId id) {
return dummyService.process(id.oldId());
}
}
The TransitionId entity is dynamically populated at runtime with both the old and new IDs. This custom deserializer approach enables the service to independently migrate its internal logic to the new ID format while maintaining API compatibility with legacy clients. Simultaneously, it provides clients with the flexibility to transition to the new ID format at their own pace, effectively decoupling the service under maintenance from one’s clients.
A significant benefit of this approach is that the endpoints remain unmodified, along with the JSON representation of the API entities involved. There is no need to introduce parallel APIs, minimizing development effort and limiting the overall impact on the system.
Additionally, since Spring is used for the implementation, it’s possible to use all the powers of dynamic property resolution and dependency injections. This allows the behaviour of the Jackson deserializer to be controlled through Spring properties and enables the implementation to be built with the usage of autowired Spring beans.
Client migration and serialization
In most cases at Picnic, a Java web client is delivered as part of the same service that exposes the API. As a result, the client will inevitably begin utilizing the TransitionId entity over time. However, since TransitionId is a compound entity containing both old and new IDs, default JSON serialization is not a viable option. Let’s consider an example:
@RestController
@RequestMapping("/api/1/site/serialization/test")
class SerializationDummyController {
@GetMapping("/{id}")
Object get(@PathVariable TransitionId id) {
return dummyService.process(id.oldId());
}
}
The default serialization of the TransitionId would look like this:
{
"old_id": "FC6",
"new_id": "NL-FC-6"
}Allowing TransitionId to serialize as a compound object would not only be incompatible with deserialization but would also create issues when using TransitionId in Spring @PathVariable and @RequestParam elements.
To address this, the serialization mechanism must be aligned with the deserialization process. This is achieved by ensuring that TransitionId is always serialized as a single ID — either the old or the new one — determined by a global Spring context variable. This approach guarantees consistency and compatibility across all usage scenarios.
For certain specialized cases, a local override mechanism was introduced. This includes annotations that allow fine-grained control over the serialization of the TransitionId entity within a specific scope, such as in the response body of a controller.
Given the following example and the default global Spring configuration set to serialize as old ID (for backwards compatibility):
@RestController
@RequestMapping("/api/1/site/serialization/test")
class SerializationDummyController {
@GetMapping("/unwrapped")
TransitionId getWithDefaultSerialization() {
return new TransitionId("oldId","newId");
}
@GetMapping("/wrapped")
TransitionIdWrapper getWithDefaultSerialization() {
return new TransitionIdWrapper(new TransitionId("oldId","newId"));
}
record TransitionIdWrapper {
@JsonValue
@TransitionIdAs(NEW_ID) TransitionId getId();
}
}
When invoking the /unwrapped endpoint, the TransitionId is serialized based on the default Spring configuration, as no custom behaviour is specified. In contrast, the /wrapped endpoint includes a local override that takes precedence over the global Spring configuration.
Local overrides are particularly useful in scenarios where the application has largely migrated to using the TransitionId and depends on global Spring configuration for serialization. They allow for a gradual shift to the new ID format within specific contexts, such as a particular controller or during database storage, without disrupting the broader application behaviour.
Switch-over time or what can go wrong?
The intermediate objective of the transition is to ensure that the target application, its web clients, and the dependent applications fully adopt the TransitionId. This approach provides significant flexibility: migrated applications can choose to expose data using either old or new IDs, while all clients remain capable of handling both formats seamlessly.
This flexibility enables independent development and evolution across applications. Furthermore, once all dependencies have transitioned to using the TransitionId web client, the migrated application can switch entirely to exposing new IDs, streamlining operations while maintaining compatibility during the transition phase.
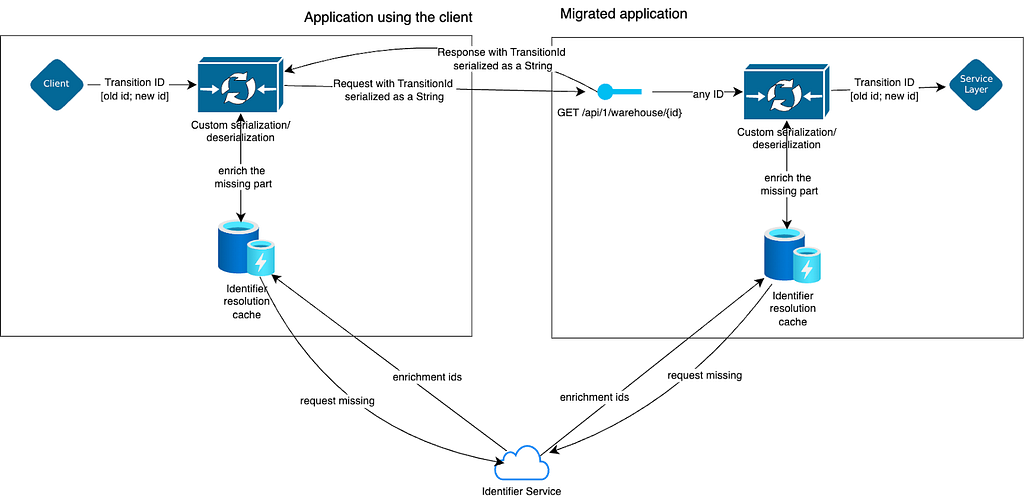
When all clients start querying the data with the new IDs, transitioning to the new ID format will be straightforward — simply replacing the TransitionId type with the new ID type.
This switch is possible due to the following reasons:
- The service already uses the TransitionId internally. With data migrations completed, the service can fully adopt the new ID format without any restrictions;
- The service receives the new ID in REST requests, meaning the use of TransitionId adds unnecessary overhead;
- The service outputs responses with the new IDs, which are easily processed by clients because they rely on the TransitionId and have the appropriate Jackson deserializer configured for this scenario.
This change will have no impact on clients, ensuring a seamless and hassle-free update.
Key learnings and the way forward
This approach has demonstrated reliable performance without introducing any overhead and has already facilitated the successful migration of numerous applications. Notably, the implementation leverages Jackson serialization and the ObjectMapper, making it well-suited for use in Spring Controllers, RabbitMQ messages, and MongoDB persistence. However, it presents additional complexity when working with relational databases, particularly when DTO entities are generated from the database schema. In such cases, manual transformations and enrichments are unavoidable.
Additionally, a dedicated library with tools designed for unit testing has proven to be highly effective. This library simplifies the testing process for users by handling data mocking and ensuring the correct application of the tool. The intricate logic behind data transformations is encapsulated within intuitive Java interfaces, allowing users to focus on testing without worrying about the underlying complexities.
All in all, the adoption of this strategy not only resolved the immediate challenges but also established a flexible and future-proof foundation for managing similar ID transitions.
Bridging the gap: A future-proof approach to identifier migration in complex systems was originally published in Picnic Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
