
TL;DR Over the past decade, Picnic transformed its approach to data — evolving from a single, all-purpose data team into multiple specialized teams using a lean, scalable tech stack. We empowered analysts by giving them access and training to the same tools as engineers, dramatically increasing speed and impact. Our investments in a lakeless data warehouse, modern analytics platform, and strong master data practices have made data a core strategic capability. This blog reflects on key milestones, cultural shifts, and personal growth along the way.
The Turning Point: Year 3
At Picnic we had a Data Warehouse from the start, from the very first order. This is quite unique, as setting up mature reporting is usually not a priority for startups. We started with PostgreSQL, laying the foundation for structured analytics early on. As the business scaled, we migrated to Redshift, enabling us to handle increasing data volumes more efficiently. In those early days, our data warehouse was rebuilt nightly from operational sources — a simple but effective way to ensure fresh, reliable insights.
By our third year, it became clear that data couldn’t just support the business — it had to drive it. Operations were scaling rapidly, and while we had solid analytics fundamentals and a robust Data Warehouse built with Kimball and Data Vault best practices, we found ourselves constantly firefighting.
The challenges were multi-dimensional (pun intended). On one hand, the growing volume of data significantly increased processing times, making it difficult to refresh the Data Warehouse overnight. With no room for error, ensuring fresh analytical data by the start of the business day became a constant race against time. On the other hand, evolving APIs led to more frequent failures in our ETL jobs, adding instability to the pipeline. At the same time, demand for data surged, but our database technology lacked the ability to efficiently isolate workloads, creating performance bottlenecks as more teams relied on the system for insights.
The pace of growth was outpacing our systems, leaving little time for structural improvements. We needed to pivot from reactive mode to strategic execution.
Bold Moves: Structure and Stack
To break the cycle, we made two pivotal changes:
- We aligned our organizational structure with long-term strategic goals.
- We adopted a lean and scalable tech stack with plenty of optionality.
At the time, a single team was responsible for everything — data modeling, warehousing, event streaming, master data management, and machine learning. That made sense early on, but it became a bottleneck. Urgent business demands would routinely derail long-term initiatives.
To solve this, we split the team into specialized tech teams, each focused on a critical domain: Master Data, Event Streaming, Data Warehousing, and Machine Learning. Each team began small, with dedicated tech and product leadership, and scaled as the company grew.
The Payoff: Fast Forward to Today
One of the most impactful shifts we made was democratizing the tools we had mastered as data engineers. We started by onboarding a small group of analysts — one per business area — with SQL. That group soon became experts in advanced analytics and helped train the next wave of analysts.
Instead of creating a gap between analytics and engineering, we gave analysts access to the same toolset — Python, dbt, SQL, orchestration frameworks. They could now build backend models and frontend GUI using the same infrastructure engineers rely on. The impact was massive. Insights and operational automations that once took weeks were now delivered in days — or even hours.
This shift also changed team dynamics. Engineers and analysts began working in shared workflows with a common language. Collaboration became more natural, and our data culture more cohesive.
Seven years on, the transformation is clear:
- Top-tier DataOps tools: Snowflake, dbt, Terraform, ClickHouse, Kafka, dbt-score.
- Mature data culture: Data modeling, governance, and quality.
- Real value from clean data: Analysts and ML engineers focus on high-impact work.
- Collaboration with autonomy: Analysts are technical and empowered by design.
Today, we’re well-positioned to solve novel business challenges and directly enhance customer experience, sustainability, and operational efficiency.
Our journey is well-documented in Picnic tech blog posts. We built our Lakeless Data Warehouse, scaled BI with Python and Snowflake, and incorporated antifragile principles in our design. We also open-sourced dbt-score, a metadata linting tool that reflects our commitment to code quality. We developed “diepvries”, a Data Vault framework for Python, and transitioned from Pentaho to distributed ETL pipelines, as described in this article. To see how our thinking evolved, check out the Q&A Data Engineering Series.
We also matured our analytics platform — enhancing observability, adopting event streaming, and embracing declarative tooling. From Snowplow app analytics and Change Data Capture, to a full migration from AWS Kinesis to Confluent Cloud, we made bold but calculated bets. Our philosophy — shared in “Turning Shadow IT Into Sunshine IT” — centers on enabling teams, not restricting them. We’ve shared our move toward declarative platforms, and gone deep on the technical side with our internal services pipeline and event streaming tech radar.
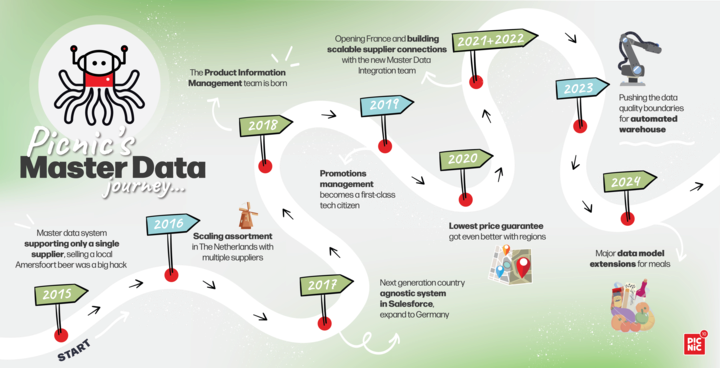
We adopted Salesforce as the platform for our custom master data management system. Its flexibility — process modeling, UI building, and validation rules — was crucial for enabling Picnic’s international expansion. Early lessons in managing critical paths are captured in our post on taming automation in Salesforce. We summed up our philosophy in “The Art of Master Data Management at Picnic”, which details how we balance standardization with flexibility and empower teams to own their domains.
A Personal Reflection: 10 Years at Picnic
This 10-year milestone is personal. I joined Picnic as the first data engineer, convinced I could build a data warehouse in a year. What came next was a journey — technical, professional, and personal. The data team grew fast with brilliant, creative people. One of the most defining shifts early on was moving from Pentaho to Python ELT, which forced us out of our comfort zone and into a new level of scale.
In year three, I stepped into a Tech Lead role and partnered with a fantastic Product Owner. Together, we tackled the challenge of making data a first-class citizen in our tech ecosystem. Letting go of hands-on coding was hard, but enabling others to thrive brought new meaning to my work.
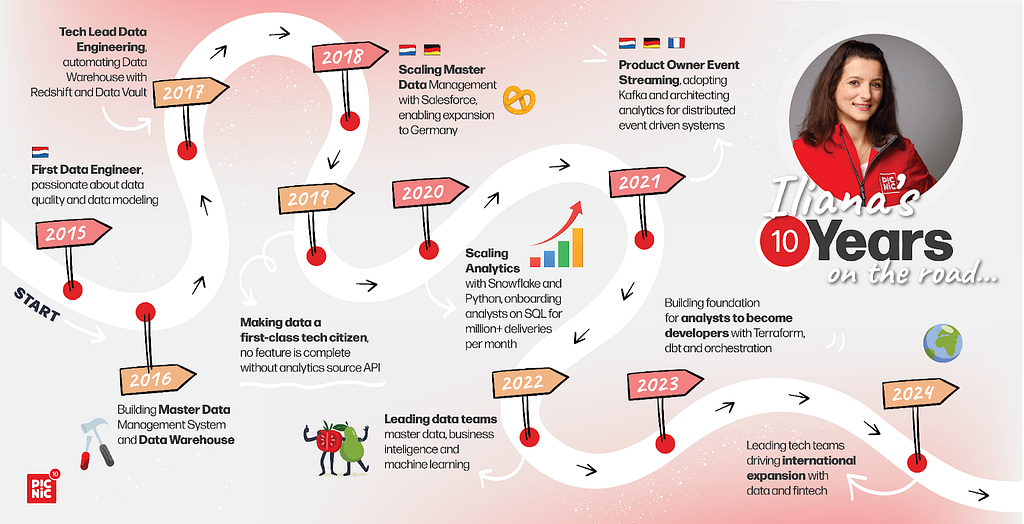
Over the years, I’ve led teams, launched international projects, and shaped data strategy. While Picnic has grown from a few dozen people to over 20k to a very different scale, I still love my work in
- Solving meaningful challenges that improve lives
- Collaborating with kind, capable, open-minded teammates
- Making grocery shopping more convenient and sustainable
I am proud of all we have accomplished so far and I am just as excited for what comes next.
A decade of scaling (real-time) analytics and master data at Picnic was originally published in Picnic Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.

 Sven Arends
Sven Arends










